システム構成
gxceed Data がどのように生成・配信されているかを示すシステム図です。 SNE Framework を理論基盤として、ローカル計算ノードで PDF を 取得・抽出し、Cloudflare Edge を経由して研究者にデータを提供します。
本図は学術論文の Figure 1 としても使用されます。
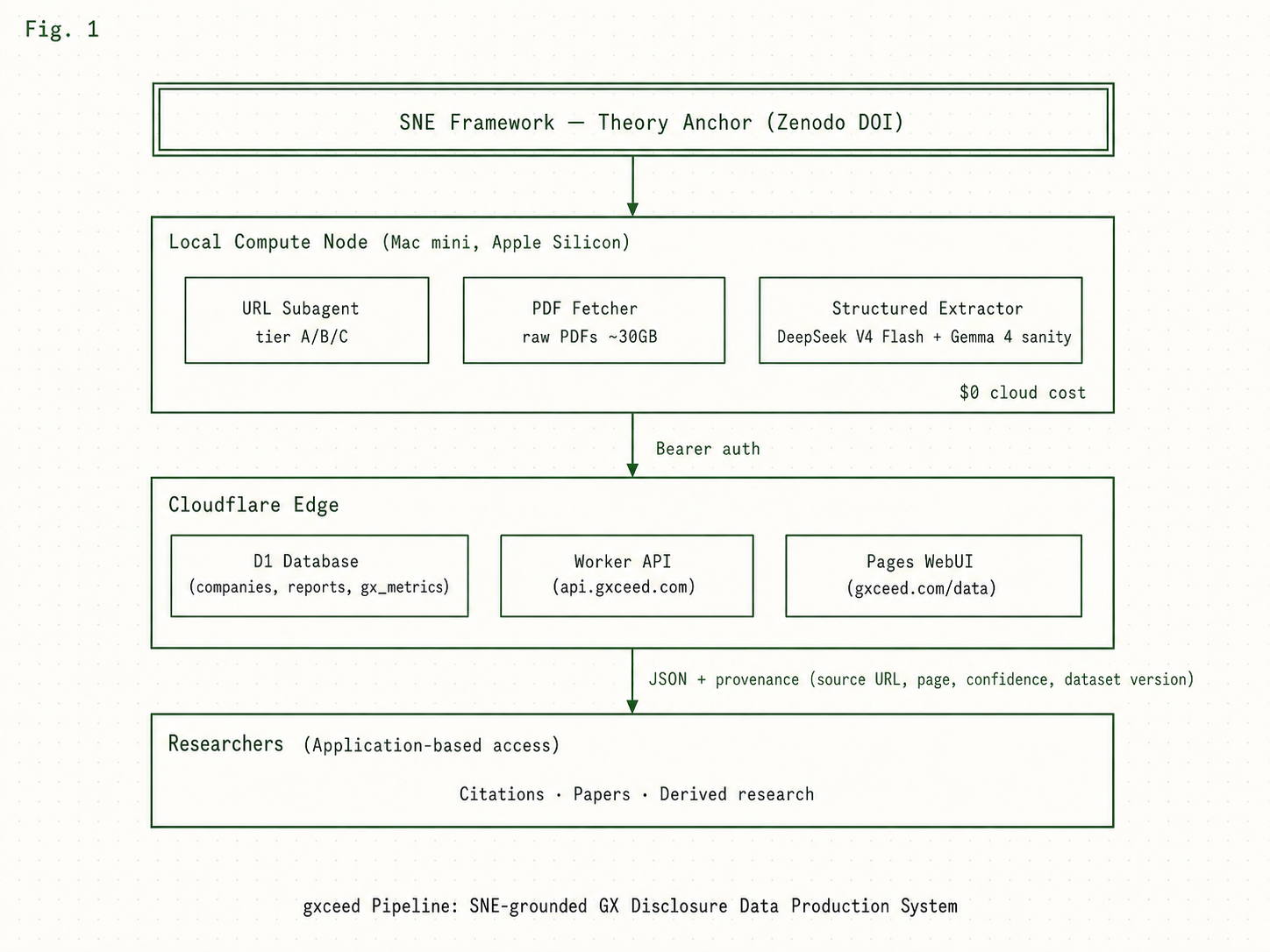
各レイヤーの役割
1. SNE Framework (Theory Anchor)
データ抽出の理論的基盤。Zenodo に DOI 化された Working paper として公開 (doi:10.5281/zenodo.19889465)。GX 開示の構造化方針 (Substance / Narrative / Expectation の三軸) は この理論から導出されます。
2. Local Compute Node
すべての PDF 取得・テキスト抽出・構造化処理が専用ローカルノード1台で完結します。 クラウド LLM を主にせず、必要時のみ外部 AI を呼び出すことで、 データセンター電力消費を最小化します。
- URL Subagent (tier A/B/C): 各社 IR ページの巡回・最新版 PDF URL の発見
- PDF Fetcher: ローカル SSD への raw PDF キャッシュ (~30GB)
- Structured Extractor: LLM で GX 数値抽出・検証
3. Cloudflare Edge
抽出された構造化データはローカルノードから Bearer 認証で Cloudflare D1 に push されます。ここから先は完全に Cloudflare の Edge ネットワーク上で 動作し、低レイテンシで研究者に配信されます。
- D1 Database: companies / reports / gx_metrics の3テーブル
- Worker API:
api.gxceed.com(Hono + Bearer 認証) - Pages WebUI:
gxceed.com/data(Next.js 15)
4. Researchers (Application-based access)
研究者は申請制で API キーを取得し、構造化データに JSON でアクセスします。 各値には provenance (出典 URL・ページ番号・抽出信頼度・dataset version) が併記されており、原典 PDF に基づく再検証が可能です。 論文・分析・派生研究での引用には 引用ガイドに従ってください。
設計方針
- クラウド LLM をデフォルトにしない: ローカル LLM と HTTP のみで完結する処理を優先し、 外部 AI は必要時のみ。データセンター電力消費を抑制
- PDF 原本をローカル保持: R2 や外部ストレージに置かず、 ローカル SSD にキャッシュ。再抽出時のコストをゼロに
- provenance 完全併記: 抽出値を「真値」と扱わず、 原典 URL・ページ番号・信頼度・モデルバージョンをすべて公開
- Dataset DOI 化: 四半期ごとに Zenodo で固定スナップショット版を発行。 API は最新を返し続けるが、論文では固定版を引用できる分離設計